Fuzzing Open-Source Software (Again) For Fun (and Hopefully Profit)
This quarter, we ran the second iteration of our "Introduction to Fuzzing" Cyber Lab project. In this project, we learned about the basics of coverage-guided fuzzing using the Honggfuzz fuzzer developed by Google. We spent the first few weeks covering topics such as build systems, compiling targets, writing harnesses, and coverage-analysis tools by applying them on old versions of open-source software to rediscover known CVEs. This culimated with the members of the project moving on to group projects where they selected an open-source project to fuzz and find new vulnerabilities in. The focus of this quarter's project was on parsers for various file formats that haven't already been fuzzed or developing a POC to rediscover a known vulnerability.
If you are interested in checking out the activities and slides for the project, you can find them at github.com/pbrucla/fuzzing-lab.
The members of our project documented their research project below. If you are interested in learning more about the project, feel free to reach out to the authors of the section you are interested in.
Table of Contents:
- PoDoFo: Nathan Cheng, Kevin Wong
- jsonxx: Isaac Khabra, Alex Acosta-You, Nikhil Jadav
- TinyXML-2: Alyssa Wong, Katie Min, Maya Zuo-Yu
- libfyaml: Hanson Zhao, Melissa Guo, Yashica Prasad
- LibRaw: Kyle Pak
- yaml-cpp: Justin Lui, Ki Riley
PoDoFo
Members: Nathan Cheng, Kevin Wong
PoDoFo is an open-source C++17 library to manipulate PDF files.
It allows PDF files to be edited, read from, and signed.
We fuzzed a set of functions from the library, including LoadFromBuffer(), ExtractTextTo(), and a variety of Get*() functions (for getting the properties and contents of a PDF file).
Methodology
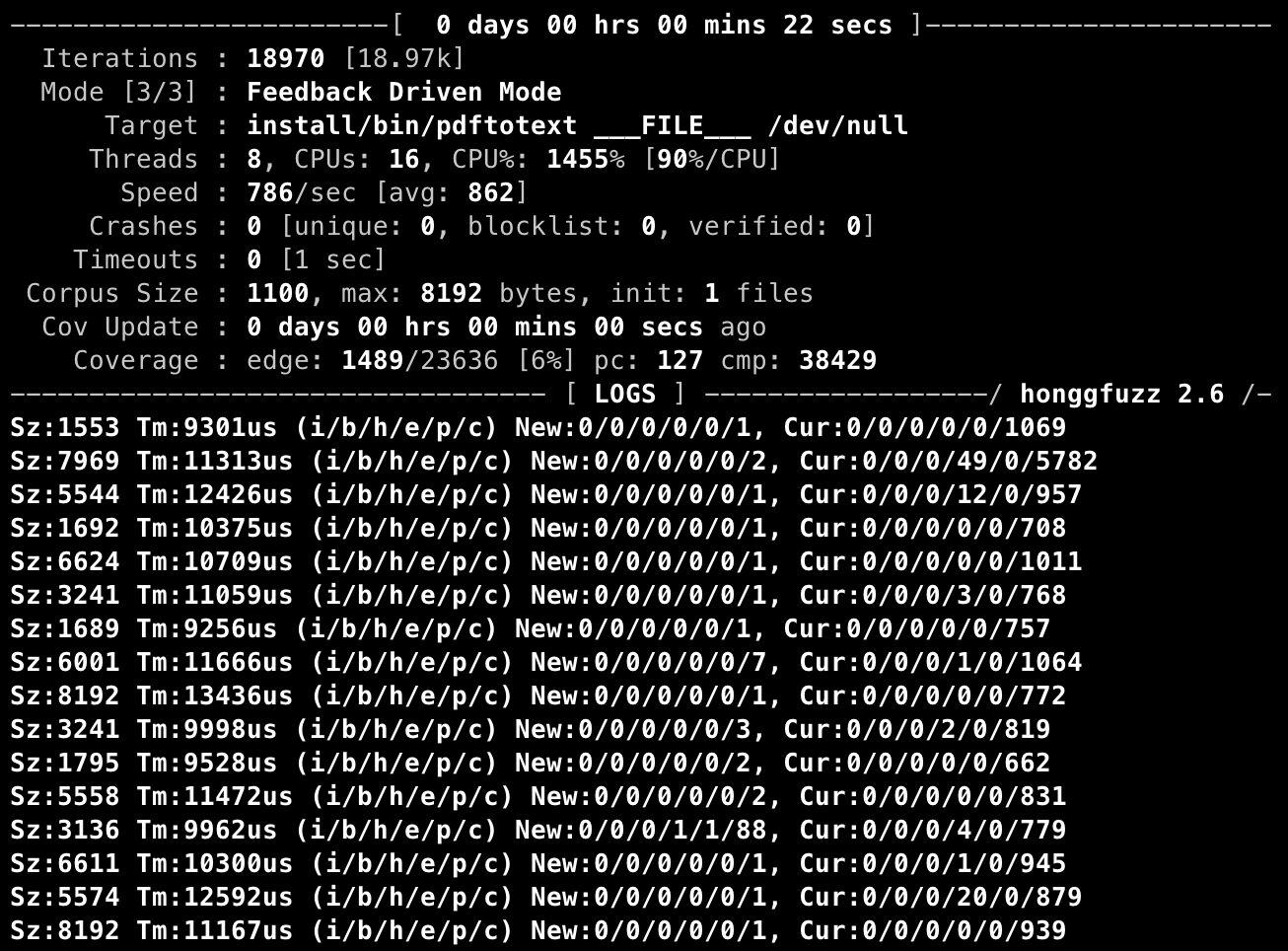
We decided to do coverage-driven fuzzing with Honggfuzz on functions that perform parsing, data extraction and manipulation on PDF files. Honggfuzz is invoked as the following command.
honggfuzz -i seed -o corpus -w pdf.dict -t 5 -P -T -- ./harness
This sets the timeout to 5 seconds and treats any timeout as a crash.
Our seed is composed of 11 PDF files, including a catalog, an essay, and an invoice, among other things. These files were selected from a web search for example PDFs, and we made sure to include PDF files with different kinds of content (text, images, etc.).
We targeted certain functions by reading their header files and associated implementation. We did this because a lot of functions and classes in the library are poorly documented, as described in the next section.
We used a shell script to compile the harness, which accelerated harness development.
We used 2 compilers to compile the library itself: hfuzz-clang++ for fuzzing and clang++ for coverage analysis.
The harness itself is written in C++ and statically linked with the PoDoFo library.
Among the fuzzed functions, ExtractTextTo() is particularly interesting because it does a lot of parsing and manipulation on the PDF structure to extract the text from a page, much like the pdftotext command-line utility.
Problems
PoDoFo has a Doxygen documentation page. Unfortunately, the auto-generated documentation was extremely un-detailed and often missing, so it was difficult to find interesting functions to fuzz. We resorted to examining header and source files in order to identify target functions of interest.
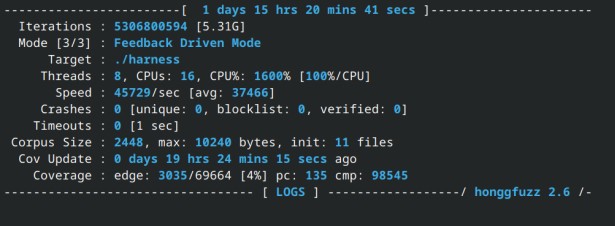
Our initial harness was also very incomplete, with its coverage plateauing at 4% (see image) before we improved the coverage to 20% by incorporating more function calls. We wanted to improve the coverage even more, but the complexity of the PDF format and the library meant that it was difficult to reach all available functions in the library.
Double Free?
After a bit of fuzzing, we got a timeout from a test case that ran for longer than 5 seconds. While investigating the timeout, we reduced our harness code (ran with the executor instead of the fuzzer) to the following:
extern "C" int LLVMFuzzerTestOneInput(uint8_t* data, size_t size)
{
try {
PdfMemDocument doc;
doc.LoadFromBuffer(bufferview { reinterpret_cast<const char*>(data), size });
for (auto* field : doc.GetFieldsIterator())
printf("Field %p\n", field);
auto p = doc.GetPages();
printf("%u pages\n", p.GetCount());
for (auto* page : doc.GetPages()) {
printf("Extracting page %u\n", page->GetPageNumber());
std::vector<PdfTextEntry> entries;
page->ExtractTextTo(entries);
}
puts("Done");
} catch (const PdfError& e) {
printf("ERROR: %s\n", e.what());
}
return 0;
}
This code looks innocent, but we were surprised when we tried to run it against the test case.
1 pages
Extracting page 1
free(): double free detected in tcache 2
Aborted
Turns out that this "double free" occurs even if we run it on perfectly valid PDF files. Curiously, when we replaced this
// (1)
auto p = doc.GetPages();
printf("%u pages\n", p.GetCount());
with this,
// (2)
printf("%u pages\n", doc.GetPages().GetCount());
the program no longer aborts. When we removed this for loop,
for (auto* field : doc.GetFieldsIterator())
printf("Field %p\n", field);
the crash disappeared as well.
In this case, we also noticed that no extraction actually occurs with (1) (the second for loop is never entered), but the extraction works correctly with (2).
So what is going on here?
Turns out that PdfDocument::GetPages() returns PdfPageCollection&, and by using auto p instead of auto& p, we accidentally created a copy of PdfPageCollection, which will have very interesting consequences.
But first, we need to learn more about how PdfPageCollection works.
Every PdfPageCollection object starts off as "uninitialized", where its internal page list is empty.
Functions such as PdfDocument::GetFieldsIterator() and PdfPageCollection::GetCount() initialize these objects, causing their page list to be populated.
This explains why we could not iterate over the pages if we call GetCount() on p, because we are initializing our copy of PdfPageCollection instead of the one owned by doc.
We also determined that the "double free" is caused by how the page list is stored in PdfPageCollection, which is a std::vector<PdfPage*>.
Since PdfPageCollection has the default copy constructor, when we copied p (already initialized) from doc, the pointers are copied as well, causing a double free in the destructor when p and doc go out of scope.
We submitted an issue and the bug is now fixed.
Results
We did not encounter any crashes of interest, but there were a handful of timeouts. We are looking into them as of the writing of this report.
Coverage
We reached a maximum coverage of 20% as of the writing of this sentence. This came after some improvements to the harness, which at one point stalled at 4% coverage.
jsonxx
Members: Isaac Khabra, Alex Acosta-You, Nikhil Jadav
jsonxx is a library that parses JSON and XML.
It's contained in just two files (one header and one C++ file), so we didn't have any issues building it; the build process was extremely simple (just had to call make).
Initially, we used a really basic seed corpus with just one file as a proof of concept, but we used examples from Adobe and produced by ChatGPT to build a bigger seed corpus when we were actually seriously looking for crashes.
We targeted the Object::parse() function initially, and later switched to functions that called a lot of other functions in the library.
The harness was extremely simple to write because it's easy to just create jsonxx:: objects and call the various functions on them.
// Example of seed corpus file
{
"a": {
"b": {
"c": {
"d": {
"e": {
"f": {
"g": {
"h": {
"i": {
"j": {
"k": {}
}
}
}
}
}
}
}
}
}
}
}
Results
No crashes were found after executing millions of iterations.
We decided to target different functions that were not being called at all after looking at the coverage reports, but these functions also did not crash after millions of iterations.
For example, we switched to the xml functions, the .json function for some of the different classes (like Object, Array, and Value), and also output operations.
Testing every function at the same time led to each iteration timing out, so we had to split them across different tests, which explains why there are so many commented out calls.
#include <cstdint>
#include <string>
#include <iostream>
#include "jsonxx.h"
extern "C" int LLVMFuzzerTestOneInput(const std::uint8_t *data, const std::size_t size)
{
std::string str((const char*)data, size);
jsonxx::Array a;
jsonxx:: Value v(str);
jsonxx::Object o(str, v);
//jsonxx::Value v;
o.parse(str);
a.parse(str);
//v.parse(str);
//std::cout << o.json();
//std::cout << a.json();
std::cout << o;
std::cout << a;
std::cout << v;
//jsonxx::reformat(str);
o.xml();
a.xml();
//jsonxx::escape_string(str);
//jsonxx::stream_string(std::cout, str);
//jsonxx::anon::json::tag();
return 0;
}
TinyXML-2
Members: Alyssa Wong, Katie Min, Maya Zuo-Yu
TinyXML-2 is a lightweight, open source parser for XML.
We fuzzed the specific function Parse(), which parses an XML for a character pointer and checks for an error.
We chose Parse() because it's supposed to take input, making it a starting point for fuzzing.
void XMLDocument::Parse()
{
TIXMLASSERT( NoChildren() ); // Clear() must have been called previously
TIXMLASSERT (_charBuffer );
_parseCur LineNum = 1;
_parseLineNum = 1;
char* p =_charBuffer;
p = XMLUtil::SkipWhiteSpace( P, &_parseCurLineNum );
p = const_cast<char*>( XMLUtil:: ReadBOM( P, & writeBOM ) );
if ( !*p ) {
SetError (XML_ERROR_EMPTY_DOCUMENT, 0, 0 );
return;
}
ParseDeep (p, 0, &_parseCurLineNum );
}
There were some issues with building it, but they were fixed by editing the prefix in the Makefile from /usr/local to /projects/ctoml/install.
(We'd originally decided to fuzz ctoml, a parser for Tom's Obvious, Minimal Language, but ran into unresolvable build issues, leading us to switch to TinyXML-2.)
The seed corpus was built with XML files randomly selected from an online corpus.
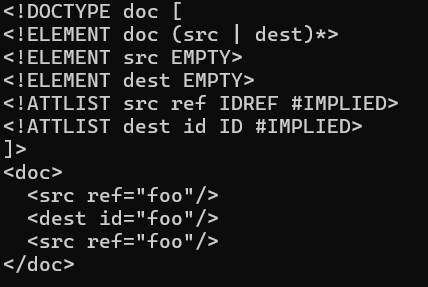
We performed coverage-guided fuzzing via writing a harness with Honggfuzz.
#include <cstdint>
#include <string>
#include <tinyxml2.h>
extern "C" int LLVMFuzzerTestOneInput(const std::uint8_t *data, std::size_t size) {
std::string str((const char *)data, size);
static const char* p = str.c_str();
tinyxml2::XMLDocument doc;
doc.Parse( p );
return 0;
}
Coverage analysis was done based off the previous projects in the lab, with a notable exception being the need to switch between C and C++ as our harness was written in C++ but the executor was in C.
-x c was used to set the language to C for the executor, and -x c++ was used to return to C++ to execute the source file tinyxml2.cpp.
While we did not find any crashes, we were able to increase our coverage to 14%, with a few timeouts.
Target: libfyaml
Members: Hanson Zhao, Melissa Guo, Yashica Prasad
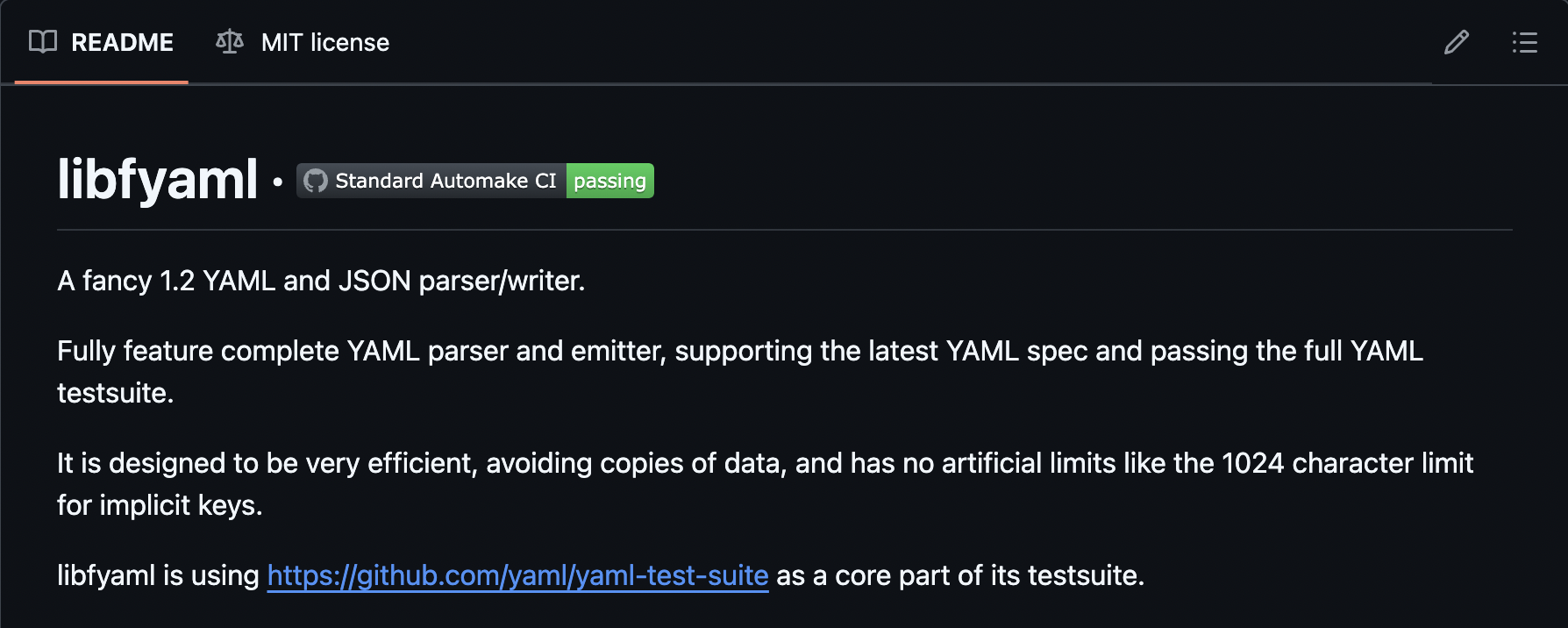
Libfyaml is a YAML and JSON parser/writer. It fully feature complete YAML parser and emitter, supporting the latest YAML spec and passing the full YAML testsuite.
YAML
From the library's README, we see that libfyaml is "a fancy 1.2 YAML and JSON parser/writer". One week into the project, we came to the unfortunate realization that we did not know what a yaml was. Some quick googling gave us "... data serialization language ... commonly used in configuration files".
Methodology
After deeper look at the example usages in the README and looking through the repository, we decided to fuzz the fy_document_build_from_string function.
We needed a seed corpus of yaml files to use as a seed corpus and used the yaml-test-suite that we found on GitHub.
A harness file is used to take inputs from the fuzzing tool and calls the specific functionality or module being tested using the prepared input.
Our harness begins by allocating a buffer which the input bytes are copied into using strncpy, ensuring it is properly null-terminated.
The function then attempts to parse the buffer as a YAML document using fy_document_build_from_string.
If the parsing is successful, the resulting document is destroyed to free resources.
Finally, the allocated buffer is freed, and the function returns 0, indicating successful execution.
This setup allows the fuzzer to systematically test different input scenarios to identify potential vulnerabilities or bugs in the YAML parsing process.
Code
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
#include <libfyaml.h>
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
char *buffer = malloc(size+1);
strncpy(buffer, data, size);
buffer[size] = 0;
struct fy_document *fyd = fy_document_build_from_string(NULL, buffer, FY_NT);
if (fyd != NULL) {
fy_document_destroy(fyd);
}
free(buffer);
return 0;
}
Problem
While fuzzing, we encountered an unusually large amount of timeouts, solved by allowing longer time limits. We then set the time limits to 10 seconds for each iteration, this resulted in less timeouts but also decreased the speed.
Result
We reach the maximum of 17% coverage rate in the end without finding any crashes.
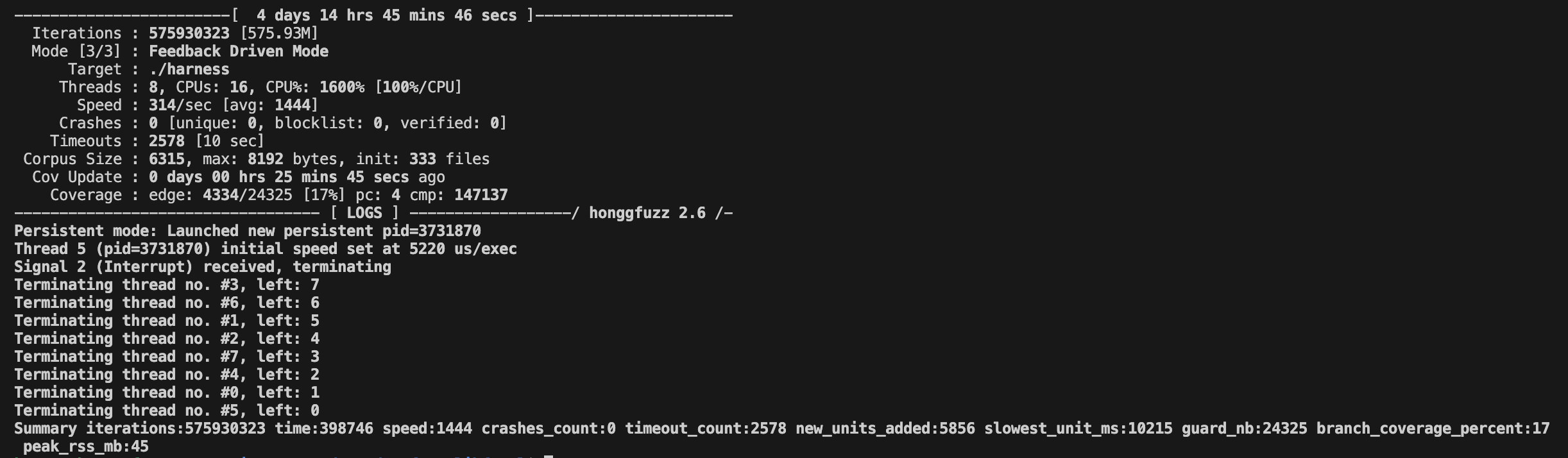
Project: LibRaw
Members: Kyle Pak
LibRaw is a library that extracts data from RAW files generated by digital cameras. It has multiple parsers which makes it perfect to fuzz.
Methodology
One of the parsers of LibRaw is a CR3 parser. CR3 is a RAW file format used by Canon Cameras. parseCR3 was fuzzed with a Honggfuzz harness.
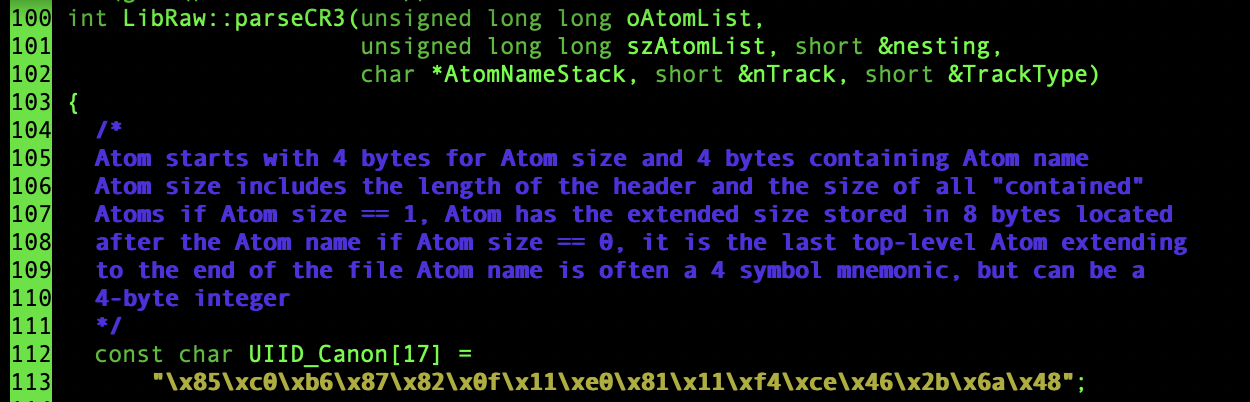
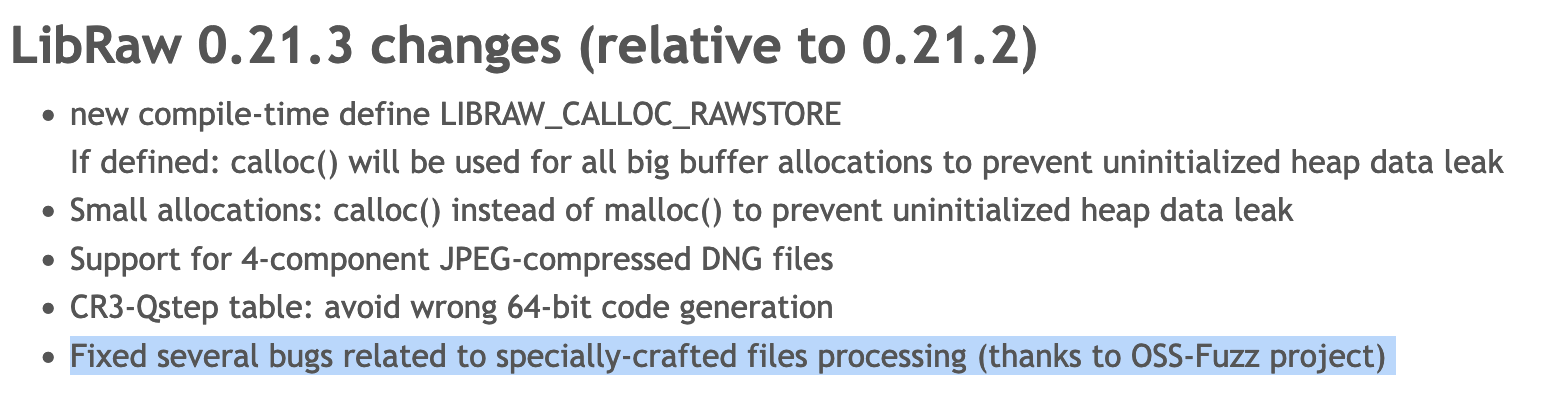
Results
The result was a stack buffer overflow. It was eventually patched.
Project: yaml-cpp
Members: Justin Lui, Ki Riley
A Quick Note
A quick disclaimer about yaml-cpp: despite being released in 2018 and being older than the latest release by two versions, yaml-cpp 0.6.0 is still the top link underneath 'Recent Releases' on the yaml-cpp GitHub page. Our group did not realize this until later; the following documentation will therefore discuss the results of fuzzing both yaml-cpp 0.6.0 and the latest release, yaml-cpp 0.8.0.

YAML Parser — Fuzzing Target
Written in C++, yaml-cpp is a YAML (1.2) parser and emitter.
We chose to fuzz the YAML::Load() function which took a string as input for parsing rather than the outdated parsing method of using YAML::Parser.
For the corpus, we created our own set of YAML files and also used the yaml-test-suite.
Harness(es)
We used two different harnesses during fuzzing since we worked independently on this section of the project. Both of them are detailed below:
#include <cstdint>
#include <string>
#include <cstdlib>
#include <fstream>
#include <yaml-cpp/yaml.h>
extern "C" int LLVMFuzzerTestOneInput(const std::uint8_t *data, std::size_t size)
{
std::string str((const char *)data, size);
try
{
YAML::Node node = YAML::Load(str);
}
catch(const YAML::ParserException& e) {}
return 0;
}
#include <yaml-cpp/yaml.h>
#include <string>
#include <iostream>
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
// Reject inputs that are too large
if (size > 8192) return -1;
try {
// Convert input to string
std::string yaml_input(reinterpret_cast<const char *>(data), size);
// Parse YAML
YAML::Node node = YAML::Load(yaml_input);
// Traverse YAML to test deeper paths
auto traverseNode = [](const YAML::Node &n) {
if (n.IsMap()) {
for (auto it = n.begin(); it != n.end(); ++it) {
// Recurse into values
it->second;
}
} else if (n.IsSequence()) {
for (auto it = n.begin(); it != n.end(); ++it) {
// Recurse into items
*it;
}
} else if (n.IsScalar()) {
// Access scalar value
std::string value = n.as<std::string>();
}
};
traverseNode(node);
// Emit YAML back to a string
YAML::Emitter emitter;
emitter << node;
} catch (const YAML::Exception &e) {
} catch (...) {
}
return 0;
}
Difficulties
The YAML::Load function throws a ParserException which we had to catch in our harness; prior to this, we were getting a large amount of supposed "bugs."
Analyzing the SIGABRT files, we were able to triangulate the cause and remedy this by catching the exception.
Results
In our original testing, we found a potential bug in yaml-cpp-0.6.0; this would've been fixed in yaml-cpp-0.8.0 considering how fuzzing yielded no crashes on the most recent release.